

K 라는 것은 군집의 개수, means 는 평균을 뜻한다.
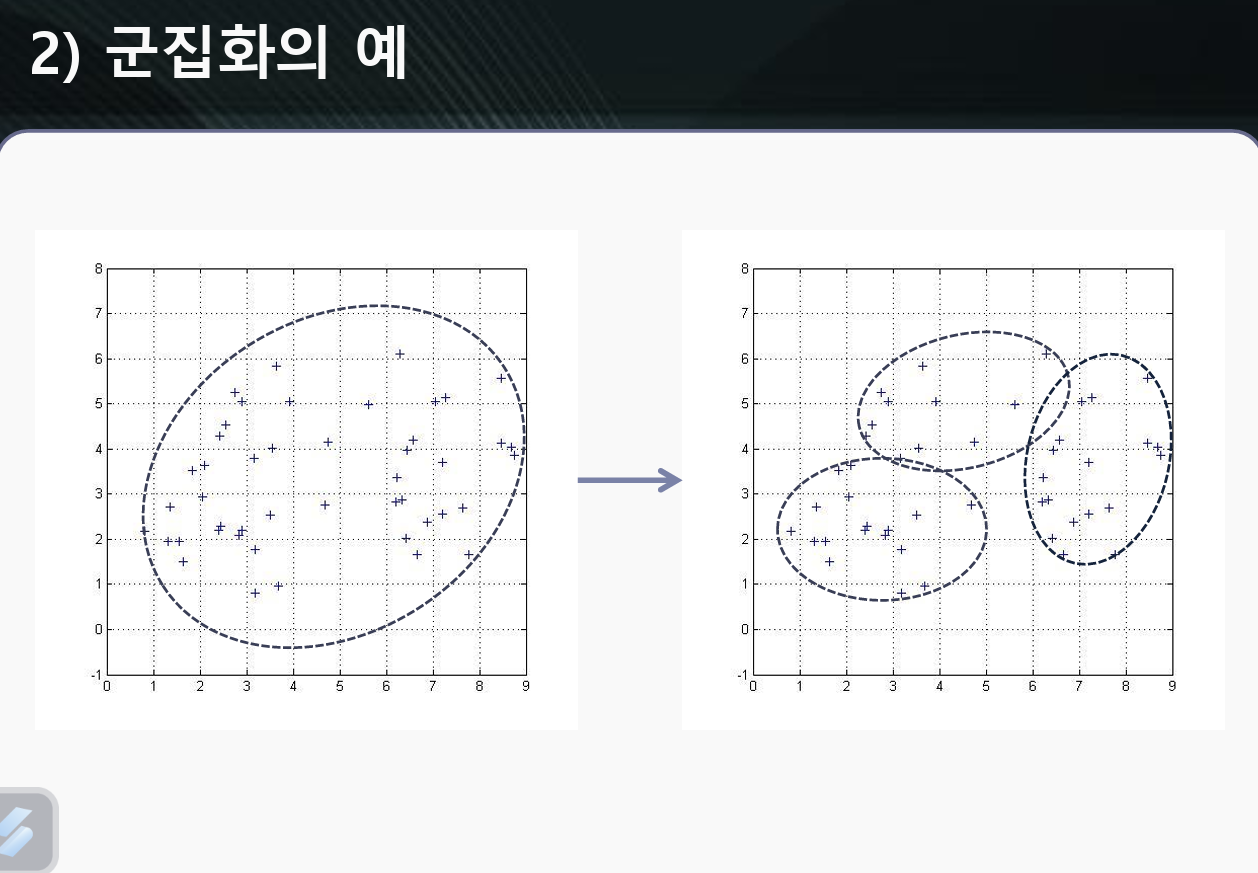
위 그림에서 오른쪽 그림은 3-means 라 하며 3개의 군집 각각의 중심을 나타낼 수 있다.

먼저 군집 m1, m2, m3 를 p3, p16, p50 으로 초기화한다. 이 때 p3, p16, p50은 랜덤값이다.
군집 m1,m2,m3 가 있을 때 p를 각각의 군집에 배정하면
p1(70, 180) 은 군집 m1 에 속한다. -> (70, 180)은 (70, 180)에 가깝기 때문에
p2(65, 150) 은 군집 m2 에 속한다. -> (65, 150)은 (65,180)에 가깝기 때문에
...
패턴을 각각에 군집에 배정하는 걸 1 사이클이라 한다.
각 j번째의 mj를 평균으로 수정한다.
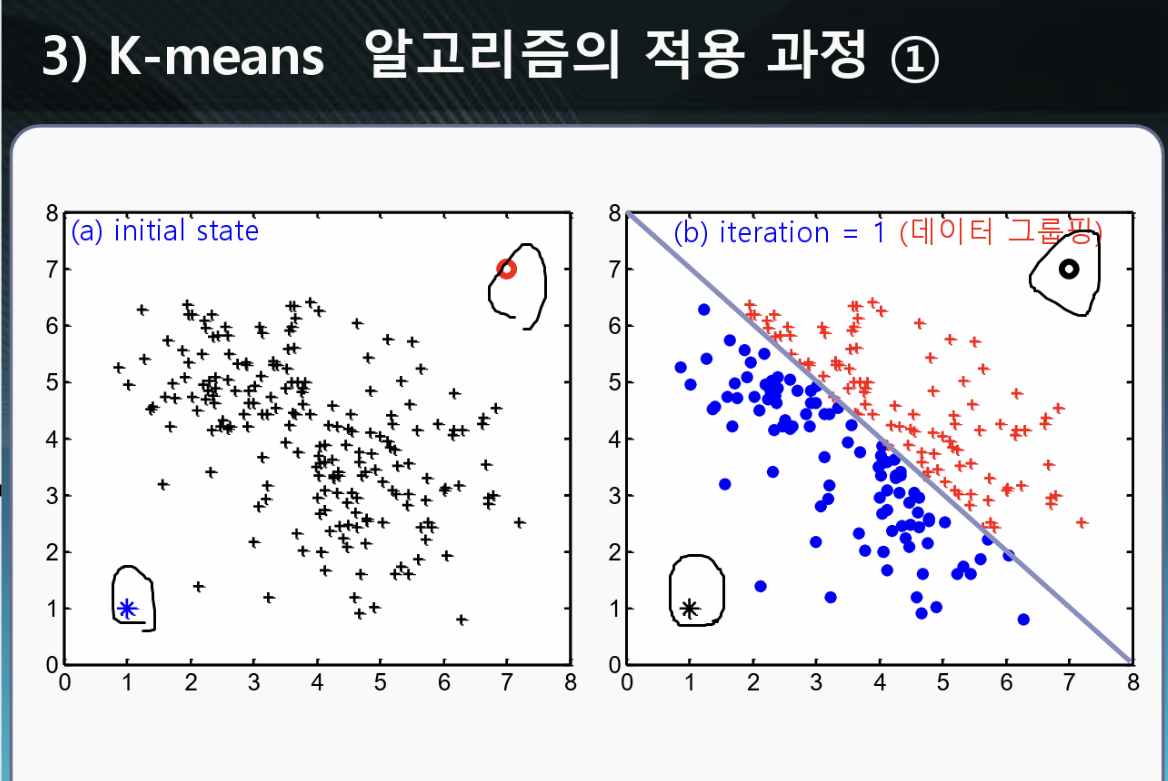
검은 원으로 표시한 두 개의 군집으로 나눈 후 각각의 데이터와 군집 사이의 거리를 계산하여
데이터를 가까운 쪽의 군집으로 배정한다.

그리고 그 군집들을 데이터의 평균으로 이동시킨다. 이걸 1cycle , 1epoch 라 한다.
또 전에 했던 과정처럼 각각의 데이터를 각 군집과의 거리를 계산하여 자기 자신의 데이터와 가까운 군집에 배정한다.
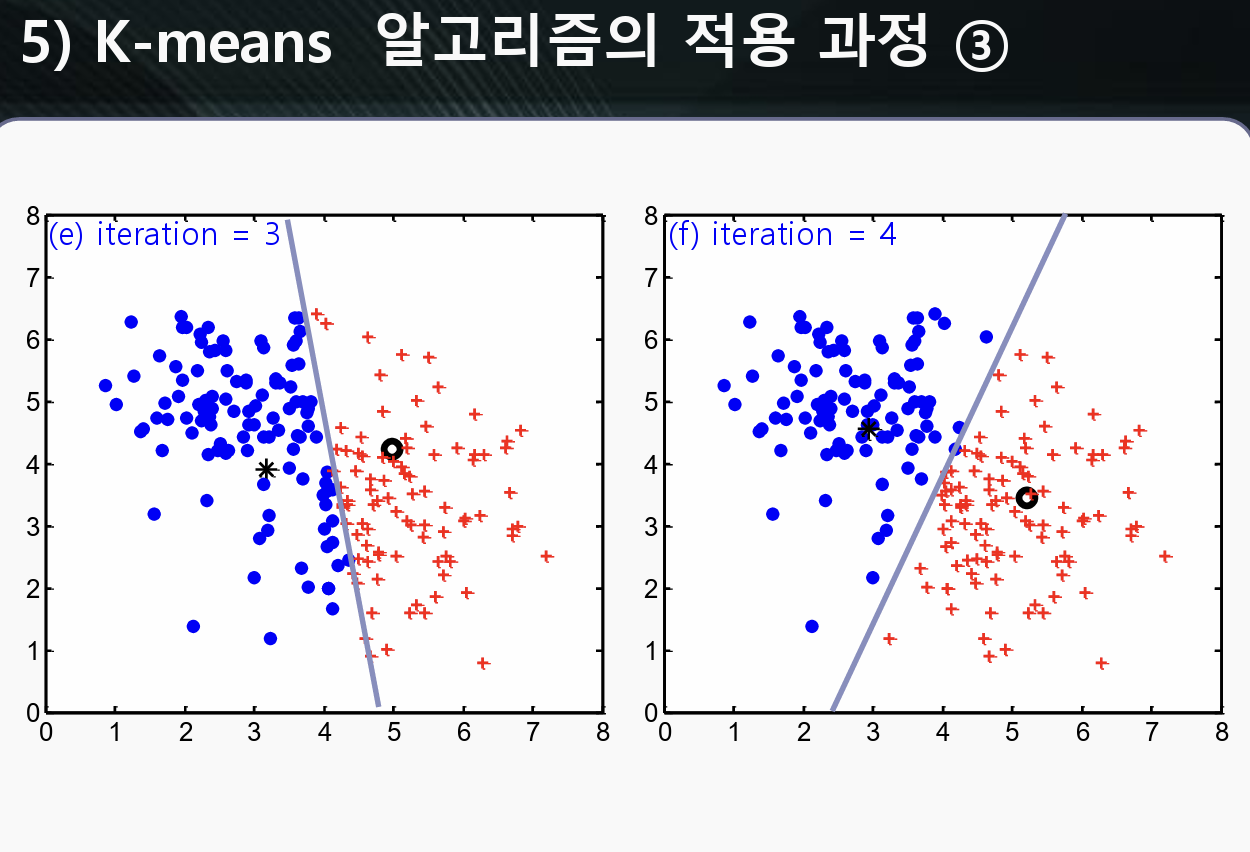
이걸 반복하면 군집의 위치가 점점 변화하며 각각의 데이터도 배정되는 군집이 달라진다.

과제
다음주 수요일까지 iris 데이터 150개를 3-means 알고리즘을 돌린 평균과 A, B, C 클래스 각각의 평균과 비교해볼것
'학교 > 인공지능' 카테고리의 다른 글
| 9번째 수업(0404) (0) | 2024.04.04 |
|---|---|
| 8번째 수업(0403) (0) | 2024.04.03 |
| 6번째 수업(0327) (0) | 2024.03.27 |
| 5번째 수업(0321) (0) | 2024.03.21 |
| 4번째 수업(0320) (0) | 2024.03.20 |