

다음 가우스 함수에 따르면 아래 그림과 같이 평균 값이 가운데 쏠린 산 모양을 나타낸다.
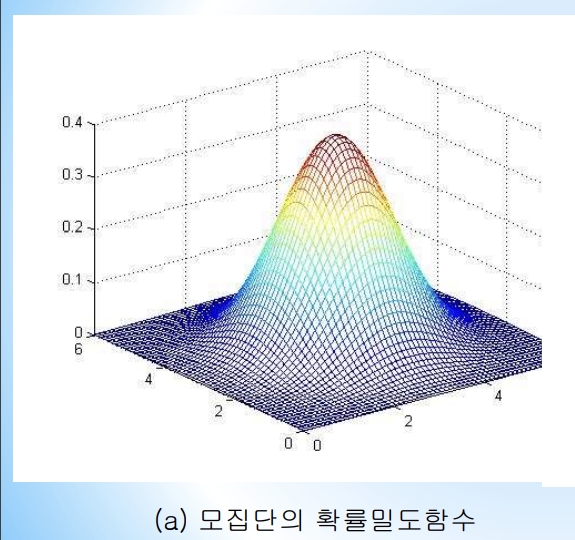
분산 : 평균에서 데이터가 퍼진 정도
분산이 크다 : 평균에서 데이터가 골고루 퍼졌다(낮은 산맥 모양)
분산이 작다 : 평균에서 데이터가 일부에 집중된 경우(가운데가 울뚝 솟은 산맥 모양)
데이터 모을 때는 분산이 작은 경우가 유리
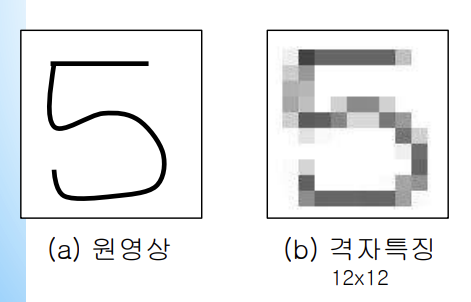
원영상이 120 x 120 의 이미지 일 때
1 x 1 의 박스 크기로 점 하나씩 지정했을 때는 총 점의 개수가 14400개가 되고
10 x 10 의 박스 크기로 점 하나씩 지정했을 때 총 점의 개수는 144개가 된다.
이처럼 점의 개수를 줄이는 것을 격자 특징이라 한다.
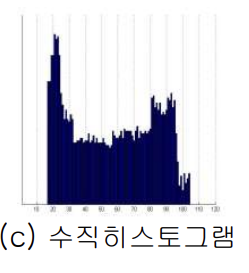
수직 히스토그램이란 위의 5의 이미지를 봤을 때 위에서 아래로 점의 개수를 탐색하여 그 수치를 그래프화한 것이다.
아래 그림처럼 위에서 아래로 점의 개수를 탐색한다고 생각하면 된다.

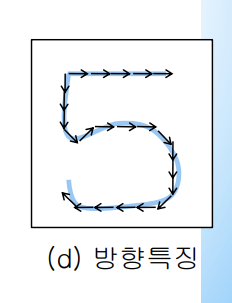
그림을 방향을 나타내는 기호를 사용하여 하나의 문자열로 만들어 문자열을 비교하여 숫자를 판가름하는 것이다.
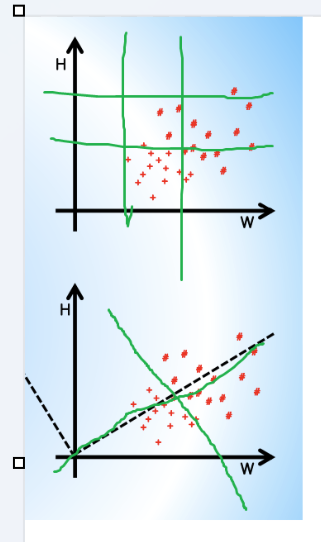
다음처럼 어떤 특징을 추출할 때 (초록색 선)가로 세로로 추출하는 건 겹치는 부분들이 많지만
아래처럼 (초록색 선)대각선으로 나누면 위 방법보다 더 정확하게 추출할 수 있다. 이걸 축변환이라고 한다.

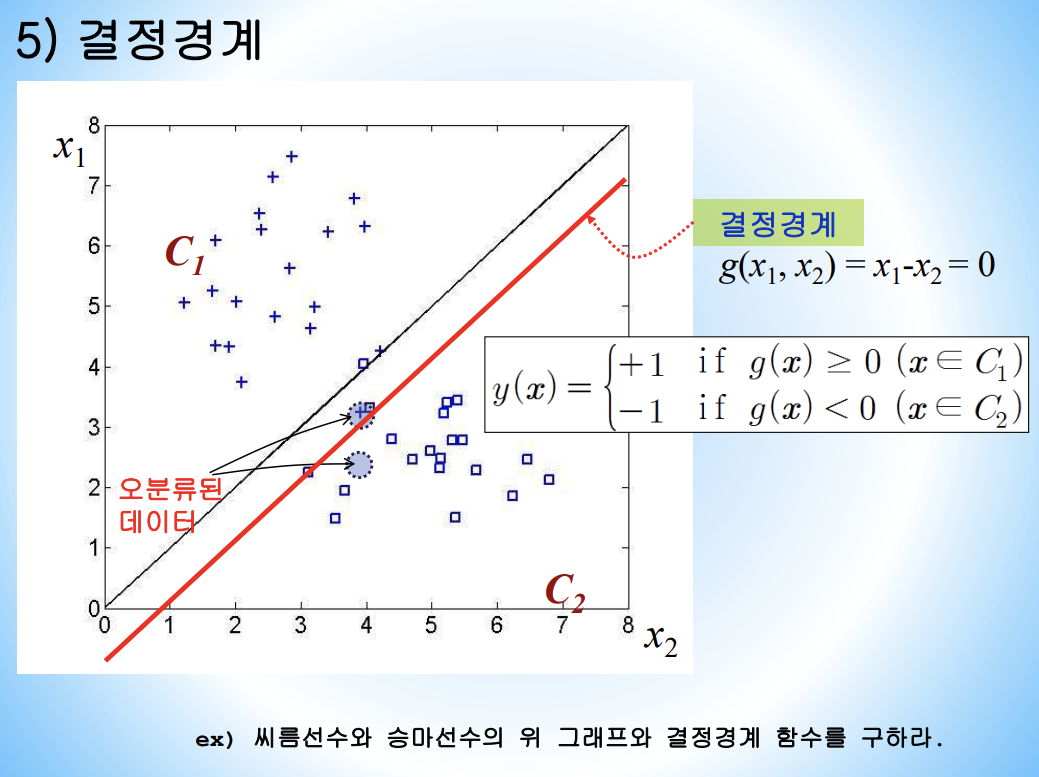
그래프에서 x1, x2 는 키와 몸무게 같은 속성을 나타낸다.

얼마나 분류를 잘했는지 측정하는 방법은 분류율을 통해 구한다.
분률율과 분류오차는 또 학습오차와 테스트오차로 나눌 수 있다.
학습데이터 1000개를 갖고 학습을 시켰는데 분류가 잘못되는 경우 학습오차라고 한다.
학습이 끝난 후 실제 현장에 가서 테스트를 하는 경우 분류가 잘못되는 경우를 테스트오차라고 한다.

제품을 출시할 때 실제 현장에 가서 테스트오차를 측정할 순 없으니
학습데이터가 500개가 있으면 400개만 학습하고
나머지 100개를 테스트하여 평균을 내서 5분류율을 측정하면
생각보다 안정되게 측정을 할 수 있다. (신뢰성을 높이기 위해)
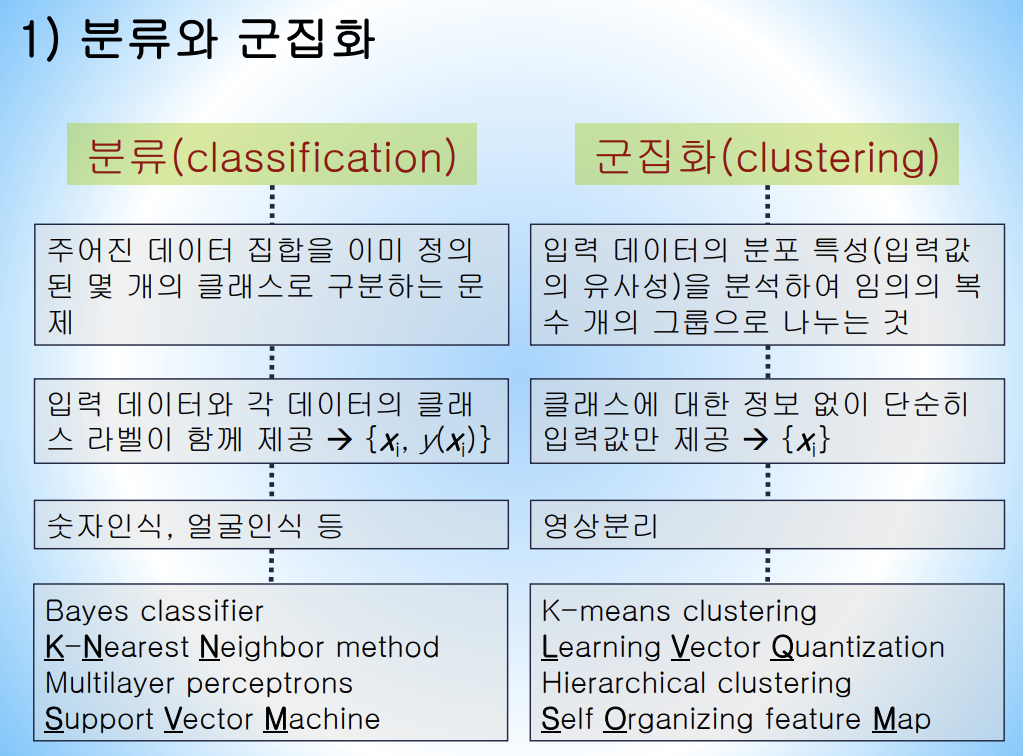
분류란 이미 정의된 집합 중에서 몇 개의 클래스로 구분하는 것이다.
군집화란 집합이 없으며 데이터만 있고 비슷한 개체끼리 나누는 것이다.
●차이 : 자기가 속한 집단이 정확하게 배정되어 있다 -> 분류 ,
자기가 속한 집단이 정확하게 배정되어 있지 않다 -> 군집화

다음 그림처럼 분류란 같은 숫자끼리 집합을 묶고 서로 다르게 생긴 데이터를 구분하는 것이다

분류는 교사학습, 군집화는 비교사 학습을 한다.
교사학습은 답에 맞춰서 학습을 시키는 것이다.
비교사학습은 답 없이 학습이 시키는 것이다.
'학교 > 인공지능' 카테고리의 다른 글
| 6번째 수업(0327) (0) | 2024.03.27 |
|---|---|
| 5번째 수업(0321) (0) | 2024.03.21 |
| 3번째 수업(0314) (0) | 2024.03.14 |
| 2번째 수업(0313) (0) | 2024.03.13 |
| 1번째 수업(0307) (0) | 2024.03.07 |